coolshell上二级指针删除单链表节点的理解
今天重新看了一遍coolshell上关于二级指针删除单链表节点的文章,想起来看这个是因为最近在看linux的hlist实现,里面用到了二级指针,我当时就想到了之前看过的coolshell上的那篇文章。那篇文章其实之前就看过,也算看懂了是怎么回事,但算不上理解,基本当个trick在看,今天又仔细想了想,有了新的想法,写出来分享一下。至于hlist的一些想法,过两天再写。
二级指针怎么删节点coolshell上写的挺清楚的,我就不赘述了。coolshell上大多数文章都写得挺好我蛮喜欢看的,但其实这篇我觉得不够好,或者说不够深入。它顶多算是介绍了下这种方法,又带着读者跑了遍代码的逻辑,到此为止了。至于为什么会用这种方法,是怎么想到的,哪些场景下可以套用这种思路,就完全没有了,这不得不说是挺可惜的。此外,这篇文章里把这种思路渲染成了一种技巧一种trick,我挺讨厌这样的。因为在我看来,到c语言这个层次了,语言本身不应该有什么奇技淫巧在里面的,任何神乎其技的实现都是有简单清晰的思路在后面支持的,而这篇文章对这段代码的解读显然违背了这点,我现在用我的理解来尝试分析一下。
先来看一下传统的写法:
1 node * remove_if(node * head, remove_fn rm)
2 {
3 for (node * prev = NULL, * curr = head; curr != NULL; )
4 {
5 node * const next = curr->next;
6 if (rm(curr))
7 {
8 if (prev)
9 prev->next = next;
10 else
11 head = next;
12 free(curr);
13 }
14 else
15 prev = curr;
16 curr = next;
17 }
18 return head;
19 }
注意到第8行的if语句,实际上就是对是否头结点两种情况的分支处理。从抽象的链表的角度来考虑,头结点需要特殊处理是因为:在单链表中,删除一个节点时需要把它的前一个节点和后一个节点连起来,而头结点不存在前一个节点,所以需要特殊处理。这个逻辑非常清晰,也非常正确,我觉得如果是这么理解c语言里的链表,那这种写法简直是天经地义,那种二重指针的才是脑子被驴踢了才会想出来的。
而现在我们尝试用一种更low-level的思路去考虑链表。在c语言中,链表节点是什么?链表节点就是一个地址加上别的数据,这个地址指示着下一个节点的位置(其实就是指针啊)。每个节点都有下一个节点的地址,这样整个链表的内容我们就都能获得了。但是这里有个问题,第一个节点怎么办?它没有前一个节点啊?ok没事有地址要访问,没有地址给你个地址去访问,所以我们会有head这个指针,用来指向第一个节点。这样我们的链表中,每个节点都有一个指针指着,而且环环相扣。
而在删除节点时,发生了什么?如果直接删除一个节点,那我们失去了什么?那个节点的数据,这个不要紧,我们删掉它说明本来就不要数据了,不是问题;下一个节点的位置,这个比较要命,我们的链表断了;上一个节点中存储的下一个节点的地址,这个其实是最严重的问题,因为此时这个地址已经没有意义了,访问会带来不知道什么后果。所以链表节点的删除需要做一些额外的工作,其实就是一句话:把之前存储当前节点地址的指针的值替换成下一个节点的地址。
你有没有发现,此时我们没有“上一个节点”这个概念了,存储当前节点地址的指针是在别的节点中还是就是head指针,这无所谓,我们只要关注指针的值就可以了。
如果还觉得迷糊,可以看下面的图:
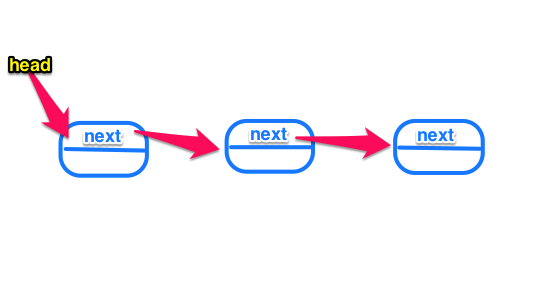
这就是普通单链表的结构,如果我们想删除一个普通节点,那么我们需要把指向下一个节点的指针赋给指向当前节点的指针。
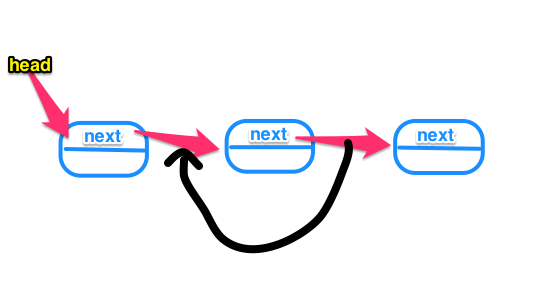
而删除头结点时,其实没有区别,我们也是把指向下一个节点的指针赋给指向当前节点的指针,只不过这个指针就是head指针,但说到底,它还是个指针。所以没有什么本质区别。
我们再回过头看下传统代码的实现
1 if (prev)
2 prev->next = next;
3 else
4 head = next;
这不就是在改指针的值么?!只是这里是通过node去访问普通节点的指针,而用head这个标识符来访问head指针。既然都是指针何必脱裤子放屁呢,用一个二重指针指向指向当前节点的指针,直接通过它修改指针的值就是了(修改一重指针的值需要用二重指针操作)。
ok最后总结一下,为什么会想到二重指针操作的写法?因为我们意识到删除操作的本质是指针值的改变,这样用二重指针去操纵指针的值就是很自然的想法。思考一个操作的本质是编程的重要组成部分,它能帮助我们更好地理解代码的逻辑,同时也能避免在外围无用操作上浪费精力,如果你想揍一头牛,去直接揍就是了,不要练什么“隔山打牛”的功夫,免得隔不同山的时候还要变化拳路。

